Speech Emotion Recognition with Transfer Learning
Classifying emotional states from speech by fusing transfer-learned spectrogram features from Inception-Resnet-V2 with classical MFCC and LPCC coefficients, then training both a Deep Neural Network and a One-vs-One SVM on the result.
The Problem
Speech is rich. Pulling emotion out of it is hard.
Speech is one of the most expressive signals humans produce, but most pipelines throw the emotion away. Classical acoustic features like MFCC and LPCC capture the spectral envelope quickly and reliably, yet they miss subtler patterns that humans pick up on intuitively.
Deep models trained on millions of natural images can capture those patterns, but they expect image-shaped inputs. The bridge: turn audio into spectrograms, run them through a pretrained vision model, and use what comes out as a feature vector. Then fuse it with the classical features and let a downstream classifier decide.
How it works
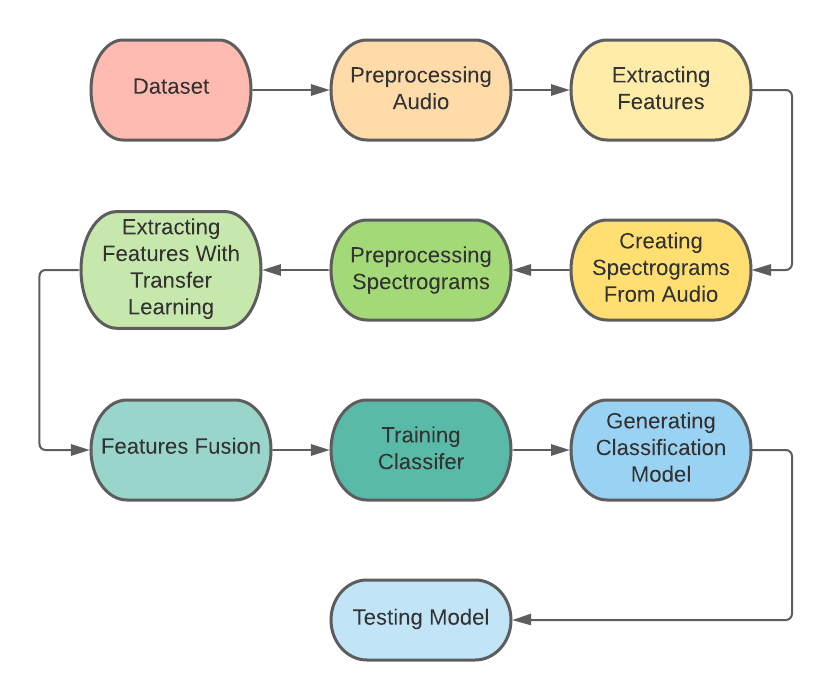
A nine-stage pipeline.
Dataset Selection
Three public emotional-speech datasets were combined: RAVDESS (1,440 audio files), CREMA-D (a 25% sample of the original), and SAVEE. Pulling from multiple sources widens the speaker, accent, and recording-condition distribution the model sees during training.
Audio Preprocessing
Sample rates were normalized and silence trimmed so every clip arrives at the next stage in a consistent format. Without this, downstream feature extractors would inherit irrelevant noise and timing variance.
Classical Feature Extraction
From each audio clip, 40 Mel Frequency Cepstral Coefficients (MFCCs) and 12 Linear Prediction Cepstral Coefficients (LPCCs) were computed. Together, these capture the spectral envelope and the vocal-tract resonances quickly and reliably.
Spectrogram Generation
The same audio was converted to a spectrogram, casting a 1D waveform into a 2D time-frequency image that a vision model can read. This is the bridge between audio and computer vision.
Spectrogram Preprocessing
Spectrograms were cast to Float32, scaled to the [-1, 1] range, and resized to 299×299 — the input shape Inception-Resnet-V2 expects.
Transfer Learning
Each spectrogram was passed through a pretrained Inception-Resnet-V2 with the classification head removed and earlier layers frozen. The penultimate output is a 98,304-dimensional feature vector capturing patterns in the spectrogram that classical features can't see — without paying the cost of training a deep model from scratch.
Feature Fusion
Four fusion strategies were tested: IR alone, MFCC + IR, LPCC + IR, and MFCC + LPCC + IR. Concatenating classical features with deep features gives the classifier complementary signals from two different views of the same audio.
Classification
Two classifiers were trained on the fused vectors: a Deep Neural Network and a One-vs-One Support Vector Machine. The DNN learns non-linear class boundaries from the high-dimensional feature space; the OvO SVM provides a strong margin-based baseline.
Evaluation
Confusion matrices, precision, recall, and F1-score were computed across all four feature combinations and both classifiers, isolating the contribution of each feature set to final accuracy.
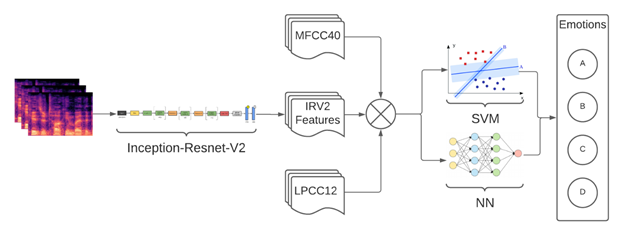
Architecture
One spectrogram, three feature streams, two classifiers.
The system fans out from a single spectrogram into three parallel feature streams (Inception-Resnet-V2, MFCC, LPCC), fuses them, and feeds the concatenated vector into either a Deep Neural Network or a One-vs-One SVM to predict the emotion class.
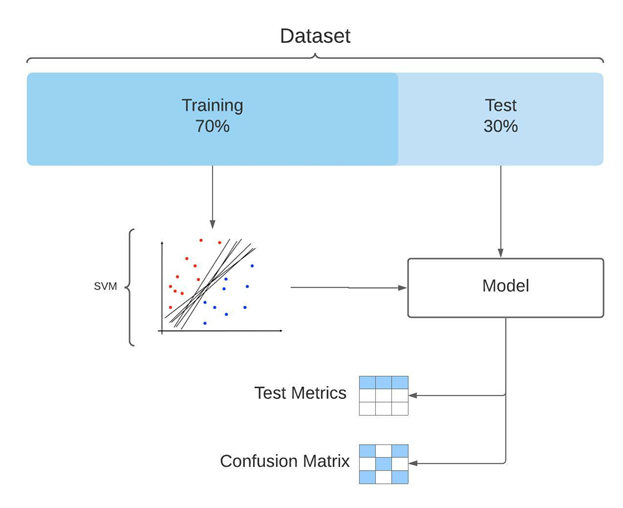
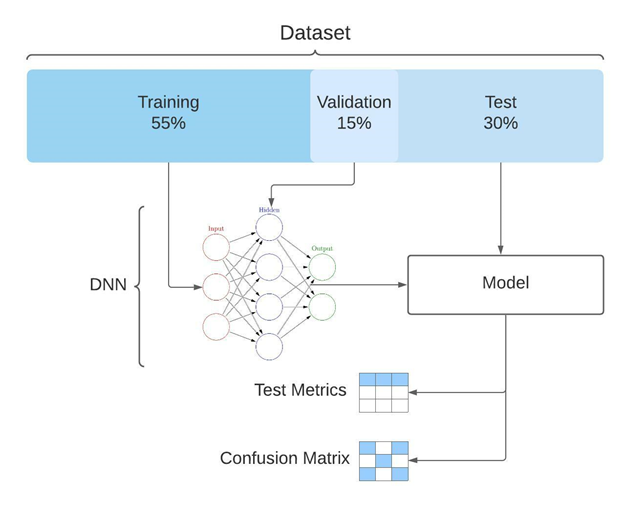
Evaluation
Held-out splits, confusion, precision, recall, F1.
The two classifier families had different evaluation needs. The SVM used a 70/30 train/test split. The DNN added a 15% validation slice (55/15/30) to monitor overfitting during training. Both were evaluated with confusion matrices, precision, recall, and F1-score across every fusion strategy.
Closing
Transfer learning, applied to a non-image domain.
The interesting part of this project wasn't any single component but the bridge: taking a model trained for image classification and using it as a feature extractor for audio, by reshaping the input modality. The same idea generalizes to anything you can render as an image — sensor traces, biomedical signals, financial time series.